滚球app(中国) 从288核到18A制程: 解码英特尔至强6+的“组合拳”

2026年的数据中心阛阓,正处于由大模子推理普及和“智能体(Agentic AI)”兴起驱动的结构性变革前夕。6月1日,英特尔全面地发布了其重磅数据中心居品——至强6+处理器(代号Clearwater Forest)及一系列新品!
智能体时期CPU价值总结与居品线再均衡

英特尔公司实行副总裁兼数据中心行状部(DCG)总司理Kevork Kechichian将数据中心责任负载证据用户的需求分为三大类:需要高密度盘算推算的横向推广(Scale-out)责任负载、需要均衡性能和数据模糊量的通用责任负载以及盘算推算密集型和AI责任负载,包括历练和推理。
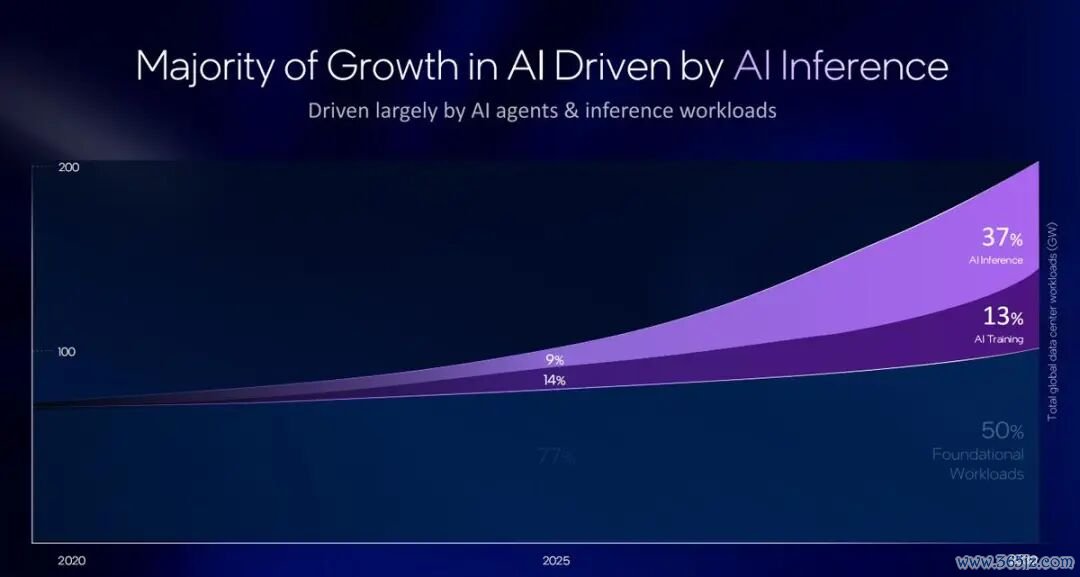
现在,智能体成为中枢场景,越来越多的需求正在向推理侧迁徙。英特尔的Tim Wilson明确提议:“从模子历练角度来看,CPU 与 GPU 之间 1:4 或 1:8 的比例。但现在,这个比例正在向 CPU 歪斜,CPU 的比重开动特出 GPU,因为咱们行将迎来智能体责任流。伴跟着这些新式智能体的出现,保执长对话的险阻文窗口执续大开,而况守护极大的险阻文容量变得至关庞大。”

是以,当年CPU将从AI推理的“协处理器”,晋升为管束多要领、多推理、多盘算推算任务的中枢“编排与更正者”。这平直修起了阛阓对CPU在当年AI责任流中脚色是否会弱化的质疑。
重返巅峰:18A制程的初次登场数据中心

本次英特尔发布十足不错界说为一次时刻“秀肌肉”。最大的看点无疑是Intel 18A制程在数据中心居品的初次范畴化应用。这是一个记号性的节点。

至强6+处理器中部分秉承的18A制程具备RibbonFET与PowerVia两大时刻,前者通过全环绕栅极结构减少了晶体管走电流,后者通过后面供电贬责了信号线拥塞与压降问题。英特尔声称带来的平直收益是:代际性能晋升高达2.26倍;与同类居品比拟,每线程每瓦性能晋升高达30%。这在能耗为王的数据中心战场上,意味着显赫的能耗本钱上风。
值得留心的是,英特尔官方在不同发布会上屡次说起客户端处理器“Panther Lake”的收效,示意18A制程产能爬坡已特出以往制程同期的良率,试图向阛阓传递量产熟谙度的信心,为后续的供应链本心铺路。
再行界说密度:搀和键合与288核的工程计算

光有先进制程还不够,英特尔在架构和封装上打出了一套更具袭击性的“组合拳”。其中枢在于冲破传统互连瓶颈的2.5D EMIB(镶嵌式多芯片互连桥)与 Foveros Direct 3D封装时刻深度交融,终了CPU、内存适度器、I/O单位的3D堆叠以及解耦设想。288核并非简便堆砌,而是通过“Tile化”设想将盘算推算单位辨认为12个独建功能区块,和谐硬件级任务更正引擎。


至强6+神勇引入了搀和键合(Hybrid Bonding)时刻将12个Intel 18A 盘算推算 tile堆叠在Intel 3制程的Active Base tile之上,终清爽极高的片间互联带宽,其平直后果即是终清爽单颗处理器高达288颗能效核(E-core)的业界巅峰级中枢密度。不仅如斯,其里面还包括2个秉承Intel 7制程I/O tile和用于互联的EMIB Tile。这种异构集成决议不仅冲破了传统单片式设想的物理极限,更以详细的功耗分区与动态资源更正,将每瓦特算力的价值推向新高。

至强6+处理器最高配备576MB的LLC末级缓存,靠近外界对多芯粒缓存探问延伸不一的担忧,英特尔给出的解答是漫衍式哈希算法,旨在将统统中枢对LLC(末级缓存)的探问平均化,幸免局部拥挤。
与上一代Sierra Forest以及AP型号比拟,在至强6+上,单路中枢数目终清爽翻倍,同期晋升了内存通说念数与内存速度,从而在平台上得回显赫增强的内存带宽。

除此以外,至强6+的居品亮点还包括:
12通说念DDR5内存:具有可推广带宽,适用于高密度系统。
96通说念PCIe Gen 5和CXL守旧:加快跨异构基础设施的数据流动。
英特尔应用动力遥测时刻(AET):终了及时、责任负载级的CPU动力和举止遥测。从英特尔至强6+处理器开动,该时刻可提高责任负载层级能耗的可见性。
高达9:1的干事器整合率:与第二代英特尔至强处理器比拟,可大幅减少占大地积,裁减TCO。
内置于芯片的可靠性机制:包括英特尔SGX和英特尔TDX,以守旧隐私和多田户部署。

此外,本次会议还败露了对于下一代代号“Diamond Rapids”的干系信息。

补皆生态的布局

此次的新品不仅仅仅CPU,英特尔还败露数据中心GPU(代号“Crescent Island”)将是首款基于Xe3P架构打造的居品,专为AI推理和智能体责任负载进行了优化。它领有增强的内存带宽、大容量内存,滚球app软件并针对云和企业级推理责任负载进行了性能调优,同期领有更低的总体领有本钱(TCO)。其内存容量晋升到高达 480GB,秉承 LPDDR内存以及高密度的后面通说念。LPDDR 内存的功耗比拟主流决议显赫裁减,或者终了将热设想功耗(TDP)适度在 350 瓦。

Crescent Island 是为了Agentic AI而生的居品,守旧最鄙俚的 AI 数据类型。这使其成为 AI 领域极具眩惑力的居品。同期,由于守旧原生 FP64,或者确保它对更鄙俚应用的守旧。
Crescent Island专为以下方面进行了优化:
AI 推理和智能体责任负载
适用于长险阻文模子的大内存容量
高服从和更低的功耗
优化的TCO

另外,今天英特尔还精致推出全新的以太网贬责决议 E835。该居品凭借高达 200 GbE 的以太网模糊量、RDMA(Remote Direct Memory Access)以及动态斥地个性化DDP (Dynamic Device Personalization)时刻,在架构设想上提高了每个中枢的带宽,专为至强 6+ 等超大中枢数目平台而打造,确保了极高的性能,从而终了网罗的全面优化。它还提供了极为丰富真实立选项,包括 2×25G、4×25G、2×100G、1×200G,并守旧欺诈英特尔的 EPCT(以太网端口确立器具)功能进行进一步的自界说。
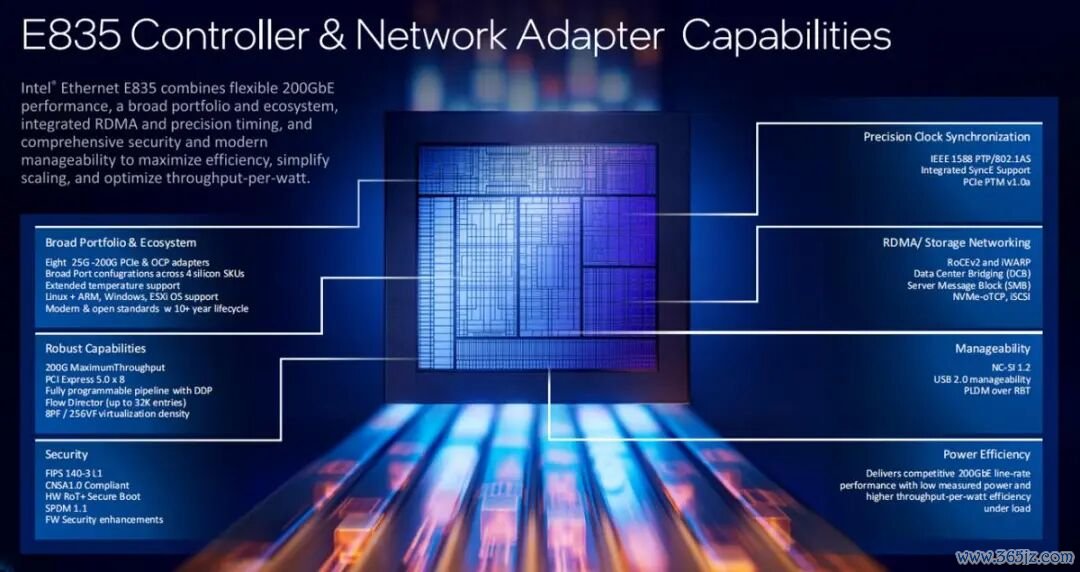
E835 通过硅芯片信任根(Root of Trust)、带签名的安全左券与数据模子SPDM(Security Protocol and Data Model)以及斥地和固件证明(Attestation)提供了刚劲的可靠保险,从而终了硬件级的身份考证和弹性保护。它还守旧鄙俚的可管束性左券,包括兼容 NC-SI 1.2 标准,以晋升运营服从。凭借跳跃 10 年的超长居品质命周期以及英特尔的官方守旧,咱们的客户不错最大化那时刻投资,裁减TCO,并确保永恒的平台安逸性和供应联贯性。
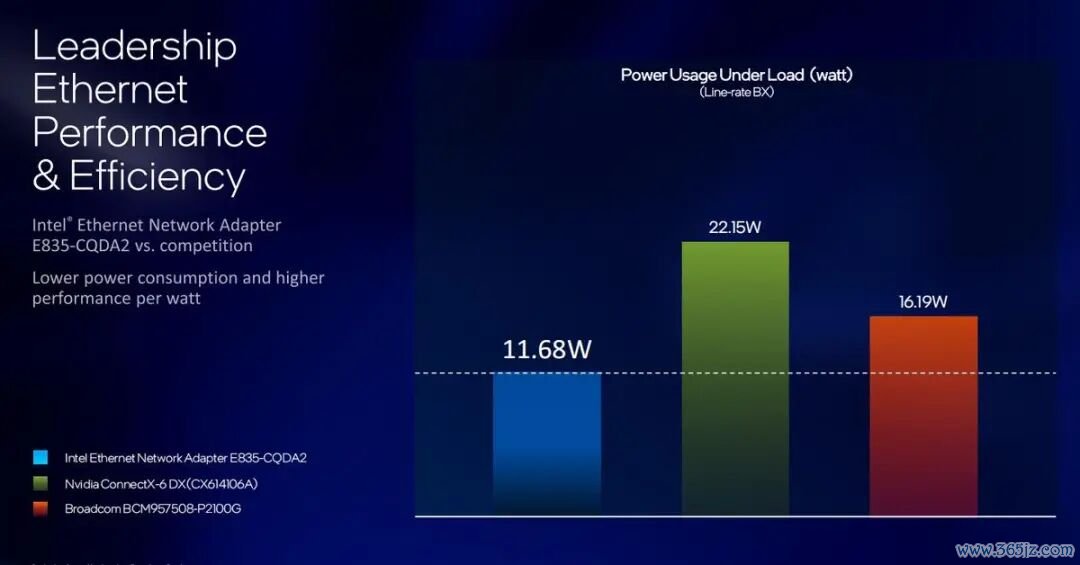
概括来看,E835 提供了全面的功能集,凭借 200 Gb/s 的网罗带宽、鄙俚的端口确立、当先的能效确认、先进的安全性和可管束性功能,突出针对现在数据中心的需求而打造。它相配妥当用来开释最新一代算力的性能,从而终了优化的数据中心确认。
小结
攻守兼备:英特尔通过18A和先进封装再行巩固了其在通用盘算推算领域的密度与能效言语权(防护),同期,通过界说CPU在智能体时期的新脚色,并与配套的推理GPU酿成协力,力争在快速增长的新兴AI负载阛阓(尽头是旯旮、推理和企业端)确立新的竞争上风(病笃)。
英特尔清爽地展示了“以千般性居品组合,应付千般化责任负载”的政策。然则,靠近竞争敌手已在高性能AI加快器领域的先发上风和稠密软件生态,其能否在“CPU+GPU”的系缚销售和一体化软件栈体验上取得客户招供,将是当年两年最大的看点之一。
一言以蔽之,至强6+ “Clearwater Forest”的亮相,不仅仅一款居品迭代,更是英特尔面向智能体驱动的新盘算推算场景,所作念的一次清爽而完好的政策出击。英特尔至强6+处理器推广了至强6眷属,专为云原生、智能体AI以及网罗密集型责任负载提供不凡的性能密度、能效与运营推广。英特尔以致强算作适度平面,弃取系统级治安,终了大范畴部署的高性能与高能效,托付为日益普及的智能体AI责任负载而设想的平台。而在这些责任负载中,不管是在数据中心如故在网罗环境,编排、数据流动以及执续推理都至关庞大。
正如英特尔公司实行副总裁兼数据中心行状部总司理Kevork Kechichian所清楚:“AI的推广之说念滚球app(中国),不在于各部件的重叠,而在于系统的协同运作。跟着AI走向智能体时期,编排、并发与数据流动成为了新的规章身分。这再次强化了一个中枢事实:CPU也曾是当代AI基础设施的适度平面。通过至强6+和以太网E835,咱们正紧密耦共盘算推算与网罗,以减少执行寰宇中的智能体责任流瓶颈,并助力其终了高效、安全的推广。”